
llama.cpp 安装使用教程
一、前因
Ollama 虽省心,但多少有点臃肿,于是乎,转战 llama.cpp ,速度快还高效
二、安装
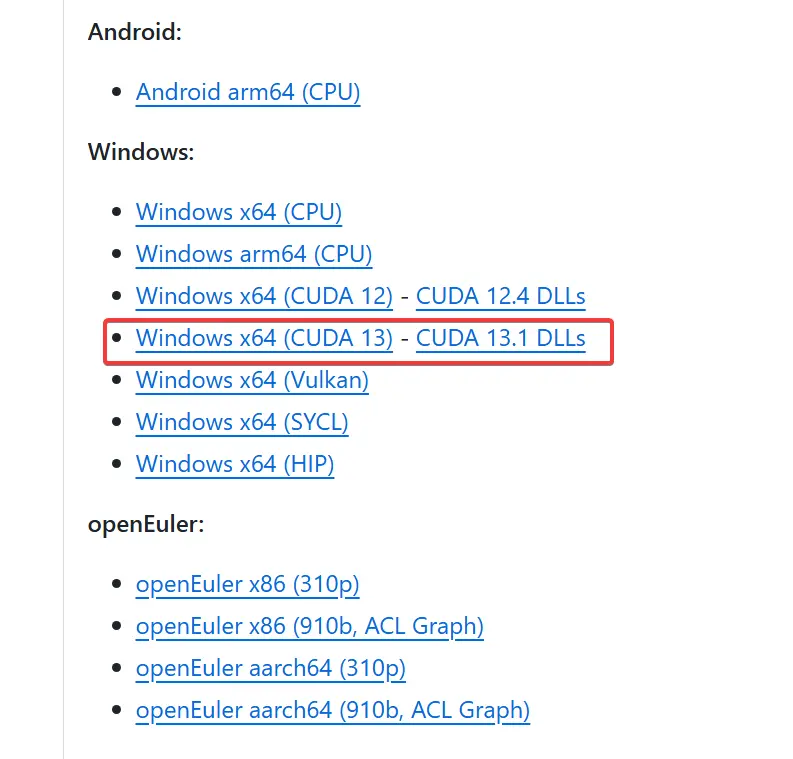
找个地方建个目录,如 llama,下载对应版本的包,解压在同一个目录下
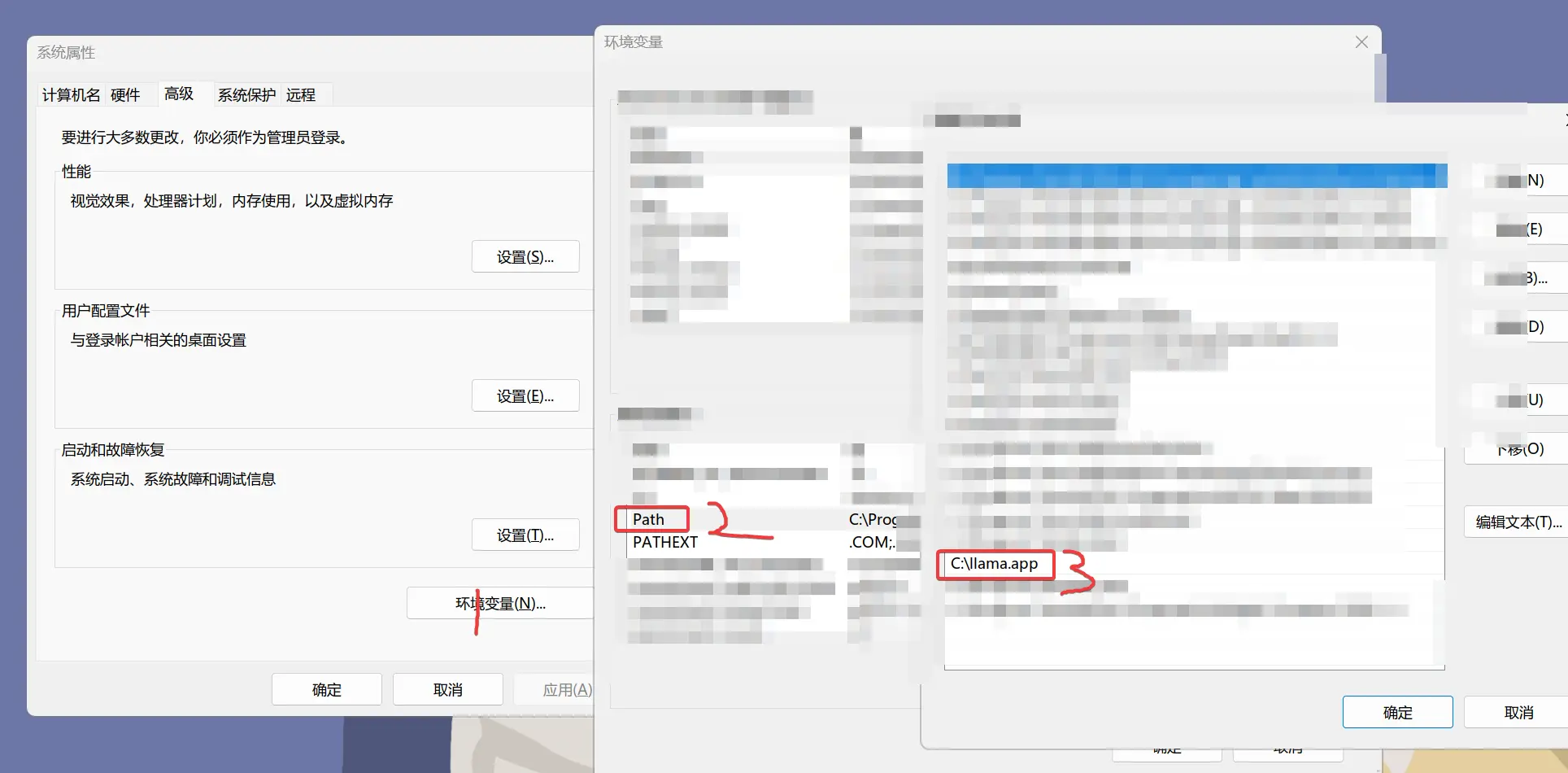
设置环境变量
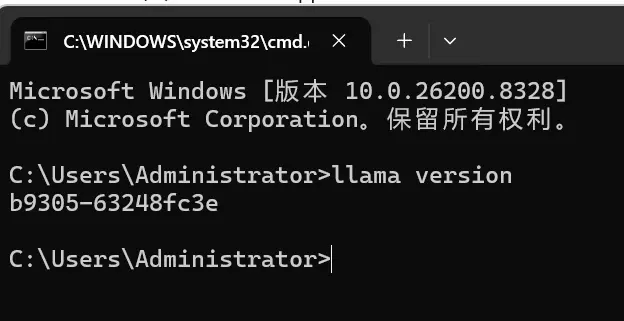
cmd 中测试版本
三、使用
从 Hugging Face 中搜索 gguf 模型,下载后放在某个目录,在当前目录打开 CMD 输入 HTTP 命令。
llama-server -m .\DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf -ngl 40 -c 4096 -t 10 -n 1024
- -m 使用的模型
- -ngl 使用 GPU 计算的层数 ,也可写成 -gpu-layers
- -c 上下文长度
- -t cpu 计算使用的线程数
- -n 一次对话生成的 token 数
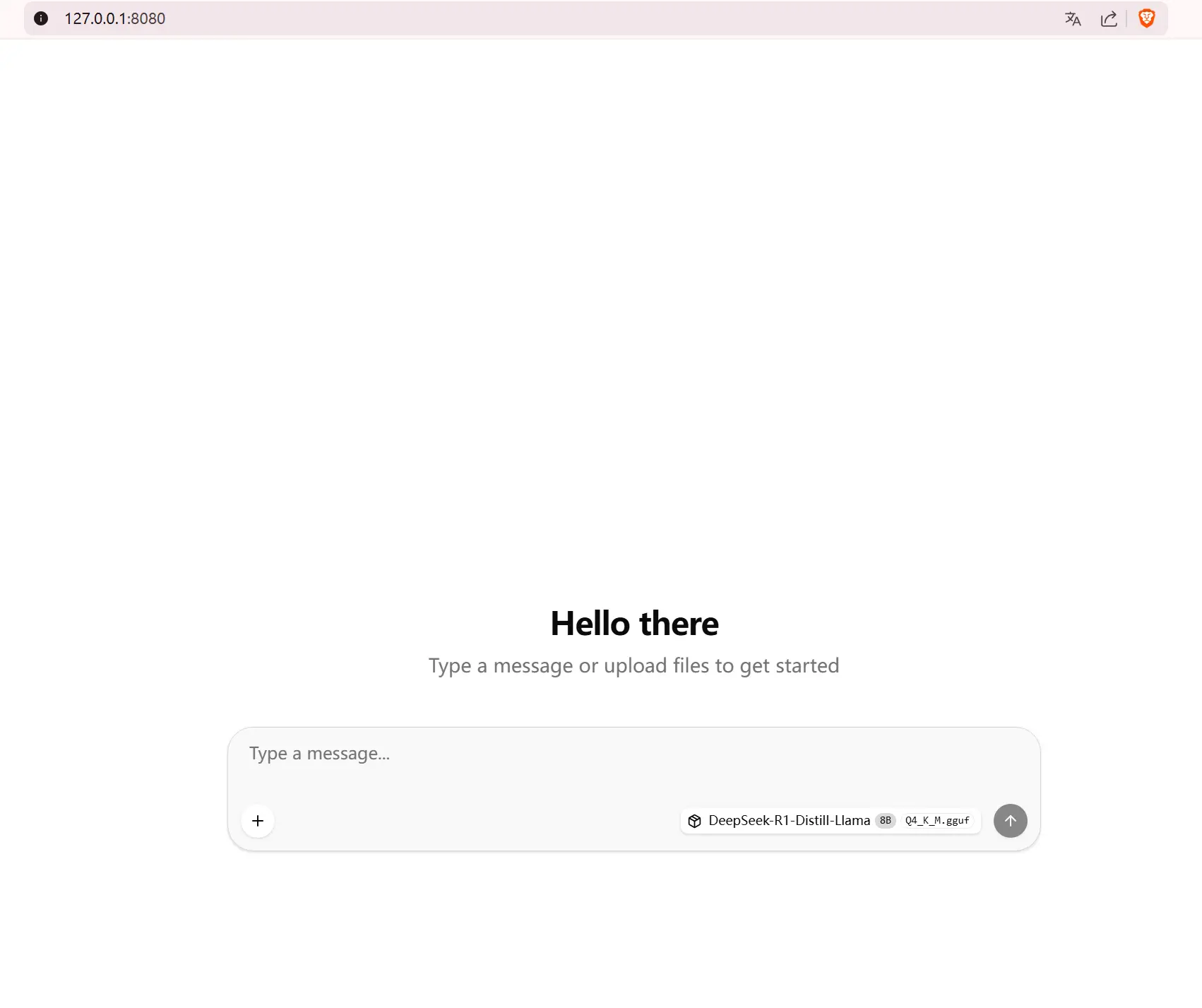
运行后打开对应的网页即可使用
四、总结
美滋滋
